Ένα από τα μεγαλύτερα προβλήματα που αντιμετώπιζαν οι χρήστες υπολογιστών κατά το παρελθόν, και συνεχίζουν να αντιμετωπίζουν ακόμη και σήμερα, αφορούσε στην επεξεργασία κειμένων που περιλάμβαναν μεμονωμένες λέξεις ή μεγαλύτερα αποσπάσματα από διαφορετικές γλώσσες. Όσοι έχουν δοκιμάσει να παραλάβουν ισπανικά κείμενα ή να αποστείλουν ελληνικά κείμενα στο εξωτερικό, θα έχουν παρατηρήσει ότι όσοι χαρακτήρες δεν περιλαμβάνονται στο λατινικό αλφάβητο αντικαθίστανται από τυχαία σύμβολα, που είτε αλλοιώνουν ελαφρά το αρχικό κείμενο, είτε το αντικαθιστούν ολοκληρωτικά με ένα ακατανόητο συνονθύλευμα χαρακτήρων. Το πρόβλημα δεν περιορίζεται μόνο στις δύο αυτές γλώσσες, αλλά αφορά στο σύνολο των χωρών που δεν χρησιμοποιούν το λατινικό αλφάβητο, όπως τη Ρωσία, την Τουρκία, την Κίνα, τις αραβικές χώρες κ.λπ. Με την διάδοση του Internet και την καθημερινή ανταλλαγή ηλεκτρονικών μηνυμάτων από και προς διάφορες χώρες του κόσμου, το πρόβλημα άρχισε να γίνεται ιδιαίτερα ενοχλητικό, αφού κατά την ανάγνωση των e-mail οι μη λατινικοί χαρακτήρες αντικαθίστανται από ελληνικά γράμματα και σύμβολα. Το συγκεκριμένο πρόβλημα, που εξακολουθεί να ταλαιπωρεί τους Έλληνες χρήστες, οφείλεται στην εσωτερική λειτουργία των υπολογιστών και στην περιορισμένη χωρητικότητα των γραμματοσειρών που χρησιμοποιούνταν κατά το παρελθόν.
Επειδή οι υπολογιστές χρησιμοποιούν αριθμούς για την εσωτερική λειτουργία τους, η αποθήκευση των αλφαριθμητικών, και όχι μόνο, συμβόλων που περιλαμβάνονται στα κείμενα που επεξεργαζόμαστε, επιτυγχάνεται με την αντιστοίχησή τους σε κάποιον μοναδικό, για καθένα από αυτά, αριθμό. Η παραπάνω διαδικασία δημιουργεί έναν πίνακα, σε κάθε θέση του οποίου αποθηκεύεται και ένας χαρακτήρας. Οι πρώτες γραμματοσειρές που χρησιμοποιήθηκαν από τους υπολογιστές, διέθεταν εξαιρετικά περιορισμένη χωρητικότητα που δεν ξεπερνούσε τους 256 συνολικά χαρακτήρες. Οι πρώτοι 128 χαρακτήρες ονομάζονται ASCII characters και αποτελούνταν από τα σημαντικότερα σημεία στίξεως, τα δέκα ψηφία και τους λατινικούς χαρακτήρες a-z και A-Z. Οι επόμενοι 128 χαρακτήρες περιελάμβαναν αρκετά ακόμη σύμβολα, αλλά και επιπρόσθετους ειδικούς χαρακτήρες που συναντάμε σε μερικές δυτικοευρωπαϊκές γλώσσες, όπως στα γαλλικά και στα γερμανικά. Το σύνολο των 256 χαρακτήρων έγινε ευρέως γνωστό με την ονομασία ANSI character set και χρησιμοποιείται από τις παλαιότερες εκδόσεις των Microsoft Windows.
Το συγκεκριμένο σύστημα κωδικοποίησης χαρακτήρων εξυπηρετούσε το λατινικό αλφάβητο, δεν μπορούσε όμως να ανταποκριθεί στις ανάγκες όλων των υπολοίπων χωρών, στις οποίες συμπεριλαμβάνεται και η Ελλάδα. Για να μπορέσουν να εμφανίσουν το αλφάβητό τους οι παραπάνω χώρες, αναγκάζονταν να χρησιμοποιήσουν τις τελευταίες 128 θέσεις του ANSI character set, στις οποίες τοποθετούσαν όχι μόνο τους επιπλέον χαρακτήρες, αλλά και διάφορα ακόμη σύμβολα όπως τη νομισματική τους μονάδα. Η πρακτική αυτή οδήγησε σε μία δυσάρεστη κατάσταση, όπου κάθε χώρα διέθετε το δικό της σύστημα κωδικοποίησης χαρακτήρων που απλά βασιζόταν, χωρίς να υιοθετεί πλήρως, στο ANSI character set. Ενώ λοιπόν οι πρώτοι 128 χαρακτήρες παραμένουν σταθεροί για το σύνολο των υλοποιήσεων, οι επόμενοι 128 διαφέρουν, με αποτέλεσμα κάθε έγγραφο που μεταφέρεται ηλεκτρονικά να εμφανίζεται με διαφορετικό τρόπο σε κάθε χώρα, ανάλογα με τους επιπλέον χαρακτήρες που έχει τοποθετήσει στις γραμματοσειρές της. Είτε πρόκειται για ένα απλό e-mail, είτε για κάποια ιστοσελίδα, είτε ακόμη και για έγγραφα που επισυνάπτονται σε e-mail, οι 128 τελευταίοι χαρακτήρες που περιλαμβάνονται στο κείμενο αντικαθίστανται και δημιουργούν σημαντικά προβλήματα στους χρήστες. Παρόμοια προβλήματα εμφανίζονται και κατά τη μεταφορά κειμένων από ένα λειτουργικό σύστημα σε κάποιο άλλο, όπως για παράδειγμα μεταξύ των DOS, Windows, Mac OS και UNIX, αφού και εκεί η κωδικοποίηση που χρησιμοποιείται από τους υπολογιστές διαφέρει.
Η προφανής λύση στο σημαντικό αυτό πρόβλημα είναι να αυξήσουμε τη χωρητικότητα των γραμματοσειρών, γεγονός που θα μας επιτρέψει να περιλάβουμε σε αυτές το σύνολο των χαρακτήρων και συμβόλων που χρησιμοποιούνται από όλες τις γλώσσες του κόσμου. Για να επιτευχθεί η παραπάνω λύση, οι υπολογιστές θα έπρεπε να εγκαταλείψουν τα 8-bit fonts με τον δυσάρεστο περιορισμό των μόλις 256 χαρακτήρων, προς όφελος ενός νέου και περισσότερο αποδοτικού συστήματος. Η δραστική αύξηση της χωρητικότητας θα μας επέτρεπε να αντιστοιχήσουμε έναν μοναδικό αριθμό σε κάθε σύμβολο ή χαρακτήρα που χρησιμοποιείται παγκοσμίως, ικανοποιώντας όλες μας τις ανάγκες.
Το σύστημα αυτό ονομάζεται Unicode και ήδη χρησιμοποιείται. Ανάμεσα στις κυριότερες προδιαγραφές του, περιλαμβάνεται η απαίτηση για υιοθέτηση του νέου συστήματος κωδικοποίησης από το σύνολο των λειτουργικών συστημάτων, και όχι μόνο από τα Windows, έτσι ώστε να είναι δυνατή η απλή μεταφορά αρχείων ανάμεσα σε δύο οποιεσδήποτε ψηφιακές πλατφόρμες. Η μερική υποστήριξή του ενσωματώθηκε ήδη από τα λειτουργικά συστήματα Microsoft Windows 95 και NT 4, ενώ οι τελευταίες εκδόσεις Windows 2000 και Windows XP βασίζονται πλήρως στο σύστημα Unicode εγκαταλείποντας το ANSI character set. Περιορισμένη υποστήριξη έχει επίσης ενσωματωθεί και στο χώρο των Macintosh, αρχής γενομένης από το Mac OS 8.5.
Το Unicode είναι ένα 16-bit σύστημα που θεωρητικά επιτρέπει την απεικόνιση μόνο 65.536 χαρακτήρων, όμως με τη βοήθεια ορισμένων προγραμματιστικών τεχνικών η χωρητικότητά του μπορεί να αυξηθεί σε πάνω από ένα εκατομμύριο διαφορετικούς χαρακτήρες. Η τελευταία έκδοσή του, που αναπτύχθηκε από τον οργανισμό Unicode Consortium, είναι η 3.2, η οποία περιλαμβάνει 95.156 χαρακτήρες που καλύπτουν δεκάδες διαφορετικά αλφάβητα και πολλά μαθηματικά σύμβολα. Στο χώρο του διαδικτύου, ο οργανισμός World Wide Web Consortium υιοθέτησε την έκδοση 2.1 που περιλάμβανε 38.887 χαρακτήρες και αποτέλεσε μέρος των προδιαγραφών της HTML 4.0. Ουσιαστικά, το Unicode δεν είναι μία γραμματοσειρά που περιλαμβάνει όλους τους χαρακτήρες, αλλά ένα σύνολο από γραμματοσειρές που χρησιμοποιούνται από κάθε χώρα και οι οποίες εναλλάσσονται ανάλογα με τις ανάγκες κάθε χρήστη.
Το Unicode έχει γίνει ήδη αποδεκτό από τις μεγαλύτερες τεχνολογικές εταιρείες παγκοσμίως, όπως οι Apple, HP, IBM, JustSystem, Microsoft, Oracle, SAP, Sun, Sybase, Unisys και άλλες, ενώ αποτελεί αναπόσπαστο μέρος των πλέον σύγχρονων τεχνολογιών, όπως XML, Java, ECMAScript (JavaScript), LDAP, CORBA 3.0, WML, κ.λπ. Παρά την ευρεία υποστήριξη του προτύπου, η πλήρης ενσωμάτωσή σου αποτελεί μία αρκετά περίπλοκη και χρονοβόρο διαδικασία. Για να διαθέτει ένας υπολογιστής πλήρη υποστήριξη Unicode και να απολαμβάνει ο χρήστης τα οφέλη που του προσφέρει στο μέγιστο βαθμό, θα πρέπει το λειτουργικό σύστημα, οι εφαρμογές αλλά και οι ίδιες οι γραμματοσειρές που χρησιμοποιεί να τηρούν με ευλάβεια τις προδιαγραφές του προτύπου. Στην πραγματικότητα, ορισμένα διαδεδομένα λειτουργικά συστήματα όπως τα Windows 95 και Windows 98 παρέχουν μερική υποστήριξη unicode, με αποτέλεσμα ακόμη και σήμερα να παρουσιάζονται προβλήματα και ασυμβατότητες. Αντίθετα, τα Windows 2000 και XP παρέχουν πλήρη υποστήριξη.
Η τελευταία έκδοση του Microsoft Office XP υποστηρίζει πλήρως το Unicode και επιτρέπει στους χρήστες να στείλουν, να παραλάβουν και να επεξεργαστούν κείμενα που περιλαμβάνουν ξένους χαρακτήρες χωρίς κανένα πρόβλημα. Παράλληλα, οι χρήστες του προγράμματος μπορούν να ανοίξουν και να επεξεργαστούν έγγραφα που περιλαμβάνουν πολλαπλές γλώσσες και δημιουργήθηκαν με παλαιότερες εκδόσεις του Office, αφού η εταιρεία έχει προνοήσει ώστε να ενσωματώσει στην εφαρμογή τους απαραίτητους πίνακες μετατροπής των κειμένων από το παλαιό στο νεότερο σύστημα κωδικοποίησης χαρακτήρων. Η υποστήριξη Unicode δεν περιορίζεται μόνο στο κείμενο αλλά περιλαμβάνει και τα πεδία document properties, bookmarks, styles, footnotes και user information, ενώ ελληνικό κείμενο, ή οποιασδήποτε άλλης γλώσσας, μπορεί να χρησιμοποιηθεί και στα παράθυρα ελέγχου όπως για την αναζήτηση αρχείων.
Η δυνατότητα αντιγραφής κειμένου μέσω της λειτουργίας copy / paste από το Word XP προς παλαιότερες εκδόσεις επίσης προσφέρεται, ενώ λειτουργεί και αντίστροφα, δηλαδή από ένα έγγραφο του Word 97 σε XP. Την ίδια δυνατότητα παρέχουν και οι εφαρμογές Access και Excel στις εκδόσεις 2000 και 2002, ενώ το Outlook 2002 υποστηρίζει τις γραμματοσειρές Unicode για το κείμενο του e-mail όχι όμως και για τα “Contacts”, “Tasks” και τα πεδία “To“ και “Subject”, όπου οι χαρακτήρες περιορίζονται σε αυτούς που περιλαμβάνονται στην επιλεγμένη κωδικοσελίδα του λειτουργικού συστήματος κάθε χρήστη.
Μία ενδιαφέρουσα παράμετρος του συστήματος Unicode, είναι η μεταβολή που προκαλεί στο τελικό μέγεθος των αρχείων. Οι εφαρμογές του Office XP αποθηκεύουν το κείμενο με μία μορφή Unicode που ονομάζεται UTF-16, όπου κάθε χαρακτήρας αντιπροσωπεύεται από δύο bytes, ή σε σπάνιες περιπτώσεις από τέσσερα bytes, προκαλώντας μία αύξηση της τάξεως του 200% και 400% αντίστοιχα σε σχέση με του παρελθόν. Ενώ λοιπόν το μέγεθος αρχείων του Office XP με πολύγλωσσο κείμενο είναι αντίστοιχο με του Office 97 και 2000, η αύξηση σε σχέση με προηγούμενες εκδόσεις που δεν υποστήριζαν Unicode ανέρχεται σε περίπου 30% έως 50%. Αντιθέτως, όταν το κείμενο περιλαμβάνει μόνο αγγλικά, το Office XP καταφέρνει να συμπιέσει το κείμενο μειώνοντας στα παλαιότερα επίπεδα το μέγεθός του.
Με δεδομένο ότι το Unicode μπορεί να υποστηρίξει δεκάδες χιλιάδες διαφορετικούς χαρακτήρες, δεν είναι δύσκολο να φανταστούμε ότι θα υπάρχει κάποιος χώρος και για το ελληνικό πολυτονικό σύστημα. Στην περίπτωση των Windows 2000 και XP που παρέχουν πλήρη υποστήριξη για πολυγλωσσικά κείμενα, το μόνο που χρειάζεται είναι ο υπολογιστής μας να διαθέτει μία γραμματοσειρά με τα κατάλληλα character sets, που στην συγκεκριμένη περίπτωση είναι τα Basic Greek και Greek Extended. Εάν δεν το φανταστήκατε ήδη, τα δύο λειτουργικά συστήματα προσφέρουν τη γραμματοσειρά Palatino Linotype που περιλαμβάνει όλους τους απαραίτητους χαρακτήρες και επιτρέπει στους χρήστες την πληκτρολόγηση πολυτονικών κειμένων.
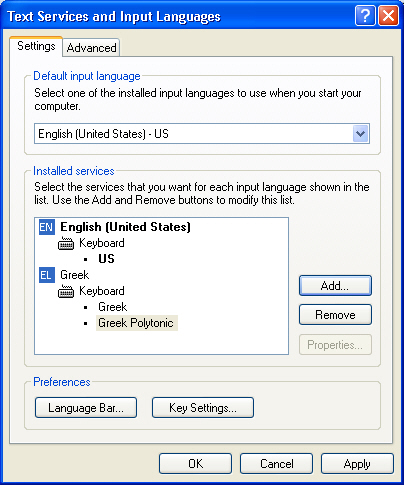
Εφόσον οι χαρακτήρες υπάρχουν στη γραμματοσειρά, το μόνο που απαιτείται είναι ένας keyboard driver που να παρέχει εύκολη πρόσβαση σε αυτούς, κατά τα πρότυπα των απλών ελληνικών και αγγλικών που χρησιμοποιεί η πλειονότητα των Ελλήνων χρηστών σήμερα. Θα μπορούσαμε βέβαια να αντιστοιχίσουμε κάποια shortcuts στους επιπλέον χαρακτήρες, όμως κάτι τέτοιο θα ήταν χρονοβόρο κατά τη διάρκεια της πληκτρολόγησης. Θα πρέπει εδώ να σημειώσουμε, ότι η εναλλαγή μεταξύ των εγκατεστημένων γλωσσών χρησιμοποιώντας το ALT + Shift, στην πραγματικότητα ενεργοποιεί το αντίστοιχο character set μέσα στην ίδια Unicode γραμματοσειρά και για το λόγο αυτό δεν αλλάζει και το όνομα που εμφανίζεται στο πεδίο Fonts της γραμμή εργαλείων του Word.
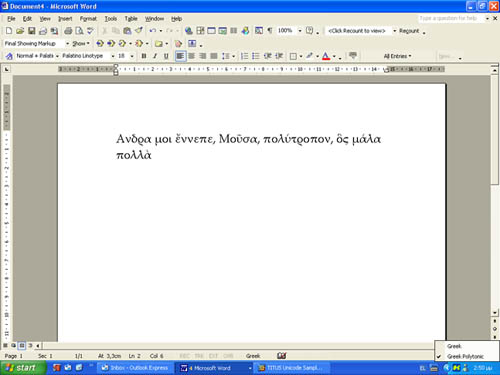
Στην περίπτωση των πολυτονικών ελληνικών, δεν έχουμε παρά να εγκαταστήσουμε το σωστό keyboard driver, ή keyboard mapper για να είμαστε πιο ακριβείς, μέσω του Control Panel/Regional Options/Regional and Language Options. Στην καρτέλα που εμφανίζεται μεταφερόμαστε στην ενότητα Languages/Details, πατάμε το κουμπί Add και στα δύο νέα πεδία επιλέγουμε Greek και Greek Polytonic αντίστοιχα. Για να γράψουμε ένα κείμενο μπορούμε να χρησιμοποιήσουμε το Word ή ακόμη και το Notepad που υποστηρίζει πλήρως Unicode UTF-8, αφού πρώτα γυρίσουμε το πληκτρολόγιο σε ελληνικά.